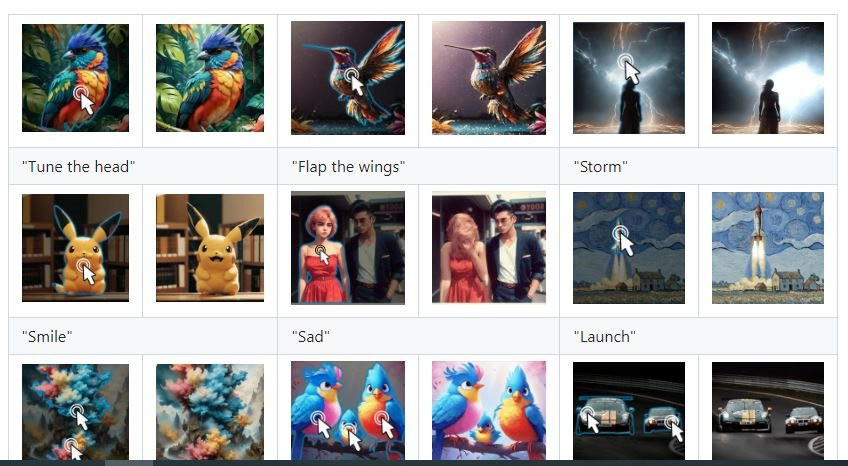
Gã khổng lồ công nghệ Tencent hôm 15.3 đã giới thiệu mô hình trí tuệ nhân tạo (AI) Follow-Your-Click hỗ trợ chuyển đổi hình ảnh thành video với sự cộng tác của các đối tác học thuật.
Đã được Tencent (Trung Quốc) đưa lên trên nền tảng GitHub của Microsoft, Follow-Your-Click cho phép người dùng người dùng nhấp vào các phần nhất định trên hình ảnh kèm gợi ý bằng văn bản đơn giản rằng muốn nó di chuyển như thế nào, sau đó ảnh tĩnh sẽ chuyển đổi thành đoạn video hoạt hình ngắn.
Dự án này là sự hợp tác giữa nhóm Hunyuan của Tencent, Đại học Khoa học và Công nghệ Hồng Kông cùng Đại học Thanh Hoa (một trong hai trường đại học hàng đầu của Trung Quốc ở thủ đô Bắc Kinh).
GitHub là nền tảng dành cho việc quản lý mã nguồn mở và dự án phần mềm. Nó cung cấp các công cụ để các nhà phát triển phần mềm có thể làm việc cùng nhau trong việc phát triển, quản lý và theo dõi mã nguồn của các dự án.
GitHub cho phép người dùng lưu trữ mã nguồn của họ trên các kho lưu trữ, theo dõi các thay đổi, quản lý phiên bản, tạo ra các nhánh để thử nghiệm tính năng mới và hợp nhất các thay đổi từ nhiều người dùng khác nhau vào dự án chung. Đây là một trong những nền tảng phổ biến nhất, quan trọng nhất cho cộng đồng phát triển phần mềm mã nguồn mở và dự án phần mềm kỹ thuật mở.
Tencent cho biết sẽ phát hành mã nguồn đầy đủ của Follow-Your-Click vào tháng 4, nhưng bản demo đã có sẵn trên GitHub. Các nhà nghiên cứu đã trình diễn một số khả năng của Follow-Your-Click ở đó. Một kết quả cho thấy hình ảnh con chim với gợi ý “vỗ cánh” đã biến thành file MP4 ngắn về con chim có màu sắc cầu vồng vẫy một bên cánh. Hình ảnh khác về cô gái đứng ngoài trời với gợi ý một từ đơn giản là “bão” đã biến thành hình ảnh động với tia chớp lóe lên ở phía sau.
Một số video và ảnh động do Follow-Your-Click tạo ra có trên GitHub
Theo bài báo học thuật của các nhà nghiên cứu từ ba tổ chức nêu trên, Follow-Your-Click được tạo ra nhằm mục đích giải quyết các vấn đề mà các mô hình chuyển hình ảnh thành video khác trên thị trường gặp phải là có xu hướng di chuyển toàn bộ cảnh thay vì tập trung vào các đối tượng cụ thể trong ảnh. Các mô hình AI khác yêu cầu người dùng đưa ra những mô tả chi tiết về cách thức và nơi họ muốn hình ảnh di chuyển.
Những nhà nghiên cứu viết trong bài đăng trên arXiv (kho lưu trữ bài báo khoa học trực tuyến): “Khung làm việc của chúng tôi có khả năng kiểm soát người dùng đơn giản hơn nhưng chính xác hơn và hiệu suất tạo ra tốt hơn so với các phương pháp trước đây”.
Việc tạo video từ văn bản đã trở thành một chủ đề nóng kể từ khi OpenAI giới thiệu Sora vào ngày 15.2. Sora có thể tạo video tối đa 1 phút với hình ảnh ấn tượng, chân thực dựa trên gợi ý từ người dùng. Mô hình AI này tạo ra các cảnh phức tạp với nhiều nhân vật, các kiểu chuyển động cụ thể cũng như chi tiết chính xác về chủ đề và hậu cảnh dựa trên những gì người dùng yêu cầu.
Trong lĩnh vực chuyển văn bản và hình ảnh thành video, Pika Labs có trụ sở tại Thung lũng Silicon, do Guo Wenjing (chuyên gia người Trung Quốc) tại Đại học Stanford (Mỹ) đồng sáng lập, là ngôi sao đang lên khác. Công ty khởi nghiệp này đã huy động được 55 triệu USD trong các vòng vốn hạt giống và vốn Series A từ một số tên tuổi lớn nhất trong ngành công nghệ.
Vào tháng 1, Tencent đã trình làng công cụ chỉnh sửa và tạo video nguồn mở VideoCrafter2, có khả năng tạo video từ văn bản. Đây là phiên bản cập nhật của VideoCrafter1, được phát hành vào tháng 10.2023 nhưng chỉ giới hạn ở các video chỉ 2 giây.
Gần như cùng thời gian đó, ByteDance đã phát hành mô hình chuyển văn bản thành video MagicVideo-V2. Theo trang GitHub của dự án, MagicVideo-V2 kết hợp “mô hình chuyển văn bản thành hình ảnh, trình tạo chuyển động video, mô đun nhúng hình ảnh tham chiếu và mô đun nội suy khung vào một đường dẫn tạo video từ đầu đến cuối”.
ModelScope, đơn vị của Damo Vision Intelligence Lab thuộc Alibaba, cũng giới thiệu mô hình chuyển văn bản thành video nhưng hiện chỉ hỗ trợ đầu vào tiếng Anh và đầu ra video bị giới hạn trong 2 giây.
Alibaba mới đây tung ra công cụ AI tạo video chân dung có tên EMO (Emotive Portrait Alive), hỗ trợ biến hình ảnh và gợi ý về âm thanh thành video người hát và nói chuyện.
Được nghiên cứu bởi Viện Điện toán Thông minh (IIC) của Alibaba cùng các tác giả LinRui Tian, Qi Wang, Bang Zhang và LieFeng Bo, EMO có khả năng "tạo biểu cảm kèm âm thanh từ nhân vật trong ảnh". Nói cách khác, EMO có thể biến một hình ảnh tham chiếu tĩnh và âm thanh giọng nói thành video người có thể nói, hát với biểu cảm tự nhiên.
So với các AI trước đây chỉ làm biến đổi miệng và một phần khuôn mặt, EMO có thể tạo nét mặt, tư thế, di chuyển phần lông mày, nhíu mắt hay thậm chí lắc lư theo điệu nhạc. Đặc biệt, phần miệng được AI thể hiện tự nhiên, đồng bộ môi chính xác.
Trong một số video do Alibaba công bố, hình ảnh sẽ biến thành video và hát các bài được nhập vào nhanh chóng. Ngoài tiếng Anh và tiếng Trung, EMO cũng hỗ trợ nhiều ngôn ngữ khác. Alibaba cho biết đã huấn luyện AI với lượng lớn dữ liệu về hình ảnh, âm thanh và video nhằm tạo biểu cảm khuôn mặt một cách chân thực thông qua mô hình khuếch tán riêng có tên Audio2Video.
"Chúng tôi muốn giải quyết thách thức lớn hiện nay là tính chân thực và tính biểu cảm trong việc tạo video từ hình ảnh và âm thanh bằng cách tập trung vào mối liên hệ cũng như sắc thái giữa tín hiệu âm thanh và chuyển động trên khuôn mặt. Phương pháp được áp dụng là tổng hợp, bỏ qua liên kết mô hình 3D trung gian hoặc các điểm mốc trên khuôn mặt, chuyển tiếp khung hình liền mạch và bảo toàn tính nhất quán trong video, mang lại ảnh động có tính biểu cảm cao và sống động như thật", đại diện nhóm giải thích.
Hiện dữ liệu của EMO đã được công bố trên Github, còn các tài liệu nghiên cứu được đăng trên ArXiv. Alibaba chưa tiết lộ khi nào sẽ phát hành công khai EMO.
Gần đây, các giáo sư từ Đại học Bắc Kinh và Rabbitpre (công ty AI có trụ sở tại thành phố Thâm Quyến, Trung Quốc) đã thực hiện một nỗ lực mới để phát triển phiên bản Trung Quốc của Sora.
Nhóm các nhà nghiên cứu này đã cùng nhau đưa ra kế hoạch Open-Sora thông qua một trang trên nền tảng lưu trữ mã nguồn GitHub, với sứ mệnh “tái tạo mô hình tạo video từ văn bản của OpenAI”.
Kế hoạch Open-Sora nhằm mục đích tái tạo một phiên bản “đơn giản và có thể mở rộng” của Sora với sự trợ giúp từ cộng đồng nguồn mở.
Theo trang GitHub của dự án này, nhóm nghiên cứu đã phát triển một khung công việc gồm 3 phần và trình chiếu 4 bản demo của các video được tái tạo ở các độ phân giải và tỷ lệ khung hình khác nhau, từ 3 giây đến 24 giây.
Các nhiệm vụ tiếp theo của nhóm gồm tinh chỉnh công nghệ để tạo ra độ phân giải cao hơn cũng như đào tạo với nhiều dữ liệu hơn và nhiều bộ xử lý đồ họa (GPU) hơn.
Kế hoạch Open-Sora được đưa ra bởi Rabbitpre AIGC Joint Lab (sự hợp tác giữa Trường Cao học Thâm Quyến của Đại học Bắc Kinh và Rabbitpre), thành lập vào tháng 6.2023. Rabbitpre AIGC Joint Lab chuyên nghiên cứu trong lĩnh vực nội dung do AI sản xuất.
Dự án Open-Sora liệt kê 13 thành viên là nhóm ban đầu, gồm cả trợ lý Giáo sư Yuan Li từ khoa Kỹ thuật Điện và Máy tính của Đại học Bắc Kinh và Giáo sư Tian Yonghong từ Trường Khoa học Máy tính. Danh sách này còn có Dong Shaoling (người sáng lập kiêm Giám đốc điều hành Rabbitpre) và Chu Xing (Giám đốc công nghệ Rabbitpre).
Bình luận của bạn đã được gửi và sẽ hiển thị sau khi được duyệt bởi ban biên tập.
Ban biên tập giữ quyền biên tập nội dung bình luận để phù hợp với qui định nội dung của Hạt giống tâm hồn.
Mỗi ngày, cặp đôi cùng nhau nấu ăn, xem phim và đi dã ngoại lãng mạn. Thực tế, Travis luôn mang Lily Rose theo bên mình mọi lúc mọi nơi – chủ yếu là vì cô ấy sống trong túi anh, với tư cách là người vợ AI.
Đài CNN cho biết năm ngoái, nhiếp ảnh gia người Anh Jack Latham dành ra 1 tháng ở Hà Nội để ghi lại hoạt động của 5 cơ sở chuyên giúp tăng lượt truy cập và mức độ tương tác trên mạng xã hội.
Trong hơn 10.000 bản ghi âm về động vật hoang dã trên thảo nguyên châu Phi, 95% các loài được quan sát phản ứng với mức độ kinh hoàng hơn nhiều trước âm thanh của một loài.
Trong giấc mơ, bạn như thể rơi từ trên cao xuống và tỉnh dậy với khuôn mặt đầy kinh hãi. Tuy nhiên, loại giấc mơ này không chỉ là ảo giác đơn thuần, đằng sau nó còn có mối liên hệ bí mật với quá trình tiến hóa của loài người.
Chăm sóc sức khỏe không phải là việc chờ đến khi cơ thể lên tiếng cảnh báo mới bắt đầu, mà là thói quen nhỏ cần duy trì mỗi ngày. Ba cuốn sách dưới đây sẽ mang đến những kiến thức bổ ích giúp bạn hiểu hơn về chăm sóc sức khỏe ngay tại nhà.
Bài viết phân tích sức mạnh của các cao thủ trong Thiên Long Bát Bộ, đặc biệt là tứ tuyệt, và đặt ra nghi vấn về vị trí của Kiều Phong. Liệu "chiến thần" Kiều Phong có thực sự xứng đáng với danh hiệu này khi so sánh nội lực với các cao thủ khác?
Chăm sóc sức khỏe không phải là việc chờ đến khi cơ thể lên tiếng cảnh báo mới bắt đầu, mà là thói quen nhỏ cần duy trì mỗi ngày. Ba cuốn sách dưới đây sẽ mang đến những kiến thức bổ ích giúp bạn hiểu hơn về chăm sóc sức khỏe ngay tại nhà.
Một người phụ nữ ở Hàn Quốc được mệnh danh trìu mến - “nữ hoàng bụng bự”, cô nổi tiếng vì có khẩu vị ăn uống cực nhiều mặc dù chỉ nặng 50kg, cao 1,61m.
"Bà ấy đã ra đi. Cuối cùng bà ấy cũng được bình yên. Không còn ống thở, không còn đau khổ. Bà ấy đã được tự do. Mẹ ơi, con biết mẹ đang mỉm cười, con nhớ mẹ", cô gái viết về ngày mẹ qua đời sau gần 5 năm chiến đấu với bệnh Alzheimer.
Diễn viên Bình An vừa khiến cộng đồng mạng dậy sóng khi chia sẻ ảnh chụp cùng Thượng úy Lê Hoàng Hiệp - gương mặt từng “gây bão” mạng xã hội và được mệnh danh là "nam thần quân đội".